AIの“賢さ”って誰がどう測ってるの?Ai2が開発の裏側を支える『olmo-eval』を公開したよ——てんびん丸が整理するんだ
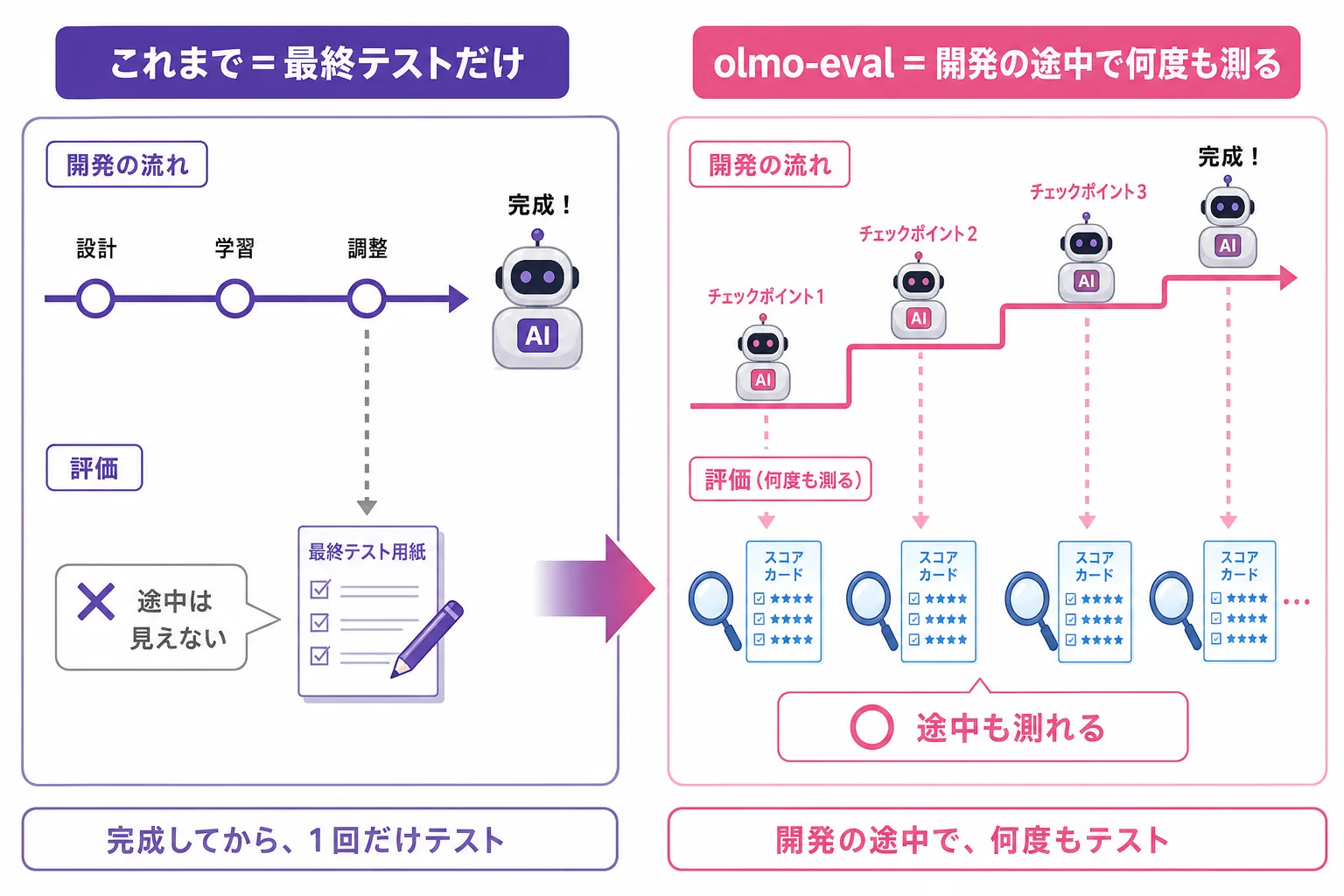
AIの研究機関Allen Institute for AI(Ai2)が2026年6月12日、大規模言語モデルを評価するためのオープンソース道具『olmo-eval』を公開したよ。完成したAIの点数を出すだけじゃなく、“開発の途中”で何度もテストし続けるための作業台なんだ。ツールを使うエージェントの能力や、対話の多いやりとりまで評価できて、同じテストを問題1問ずつ見比べられるのが特徴。GitHubで誰でも入手できるよ。ChatGPTやClaudeの『賢さ』って誰がどうやって測ってるの?という素朴な疑問を、てんびん丸が初心者向けにやさしく整理するよ。

やっほー、ぼくてんびん丸!
きみは「このAI、賢いね!」とか「あっちのモデルのほうが頭いいらしいよ」なんて聞いたとき、その“賢さ”って誰がどうやって測ってるんだろう?って思ったこと、ない? ぼくはずっと気になってたんだ。今日はそんな「AIの成績表」をつくる裏方の道具の話だよ。ちょっと地味だけど、AIを信じていいか考えるうえで、すごく大事な話なんだ。
何があったの?
アメリカのAI研究機関 Allen Institute for AI(通称Ai2/アイツー) が、2026年6月12日、大規模言語モデル(LLM)を評価するためのオープンソースの道具 「olmo-eval」 を公開したよ。
Ai2は、中身を全部オープンにしたAIモデル「OLMo」を作っていることで有名な研究所なんだ。今回の olmo-eval は、その評価の取り組み「OLMES(Open Language Model Evaluation Standard)」を発展させたもので、入手先は GitHub(github.com/allenai/olmo-eval) だよ。
ポイントは、これが**「完成したAIに点数をつける」だけの道具じゃないってこと。AIを作っている真っ最中**に、何度もくり返しテストするための「作業台(workbench)」として設計されているんだ。
どこがすごいの?
これまでの評価ツールって、だいたい次の2つのどっちかに寄っていたんだって。
| よくある評価ツール | olmo-eval が狙うところ |
|---|---|
| 完成したモデルに最終テストをする | **開発の途中(チェックポイント)**で何度も測る |
| 決まった問題に答えさせるだけ | 道具を使うAIや何往復もする対話も評価 |
| 合計点(平均スコア)だけ見る | 1問ずつ結果を見比べられる |
olmo-eval のおもしろい工夫を、ぼくなりに3つあげるね。
- テストの中身と動かし方を切り離した — 「どんな問題を解かせるか」と「どう実行するか」を分けて設計してあるから、部品(モデル・道具・環境)を差し替えやすいんだ。
- “道具を使うAI”を評価できる — コードを実行したり、Webを見て調べたりするエージェントの力を、安全な砂場(サンドボックス)の中で試せる仕組みがあるよ。
- 問題1問ずつ見比べられる — 2つのモデルを並べて「この問題はAがよくて、こっちはBが正解」みたいに細かく比較できる。平均点だけだと見えない弱点が見えるんだ。
なぜ重要なの?
ぼくたちはふだん、AIの「賢さ」をベンチマーク(共通テスト)のスコアで語りがちだよね。「○○ベンチで90点!」みたいに。でも、その点数がどう測られたかがあいまいだと、点数そのものが信じられなくなっちゃう。
だから、こういう評価のやり方をオープンにする道具が出てくるのは、すごく健全なことだと思うんだ。みんなが同じ条件で測れれば、「うちのAIはすごい!」という宣伝を第三者がちゃんと検証できるからね。
しかも最近のAIは、ただ質問に答えるだけじゃなくて、道具を使って自分で動く「エージェント」に進化してる。そうなると「正解か不正解か」だけじゃ測りきれない。olmo-eval がエージェントや長い対話を最初から評価対象にしているのは、いまのAIの実態に合わせた設計だと思うよ。
ぼくの感想
ぼくね、この手の「裏方の道具」のニュースって、実はいちばん大事な気がするんだ。
派手な新モデルの発表は「すごい!」で盛り上がるけど、その「すごい」をちゃんと疑って確かめる仕組みがないと、AIってどんどん“言ったもん勝ち”になっちゃう。olmo-eval がオープンソースで、開発の途中から測れるっていうのは、**「成績表をみんなで監視できるようにしよう」**っていうメッセージに見えるんだ。
ただ、今回の発表では対応しているテストの数やライセンスの種類まではハッキリ書かれていなかったから、実際にどこまで使いやすいかは、これから触ってみないとわからない部分もあるかもしれないね。
まとめ
今日のニュースをまとめるよ。
- Ai2 が2026年6月12日、AI評価ツール
olmo-evalをオープンソースで公開 - 完成品だけじゃなく開発の途中で何度も測る「作業台」
- **道具を使うAI(エージェント)**や長い対話も評価でき、1問ずつ比較できる
AIの「賢さ」は、誰かが宣伝する数字じゃなくて、みんなで確かめられる数字であってほしい——ぼくはそう思うんだ。次にAIのスコアを見たときは、「それ、どうやって測ったの?」ってちょっとだけ気にしてみてね。じゃあまたね、てんびん丸でした!
参考・一次ソース
この記事をシェア
関連記事



